En planification de la demande, la précision des prévisions sert à évaluer dans quelle mesure une prévision reflète la demande réellement observée. Elle est souvent mobilisée comme un indicateur de performance, au même titre que le taux de service ou le niveau de stock.
Dans de nombreuses organisations, y compris chez Pawa, la précision des prévisions est souvent exprimée à travers un score synthétique, dérivé d’une erreur relative et utilisé comme indicateur de lecture rapide.
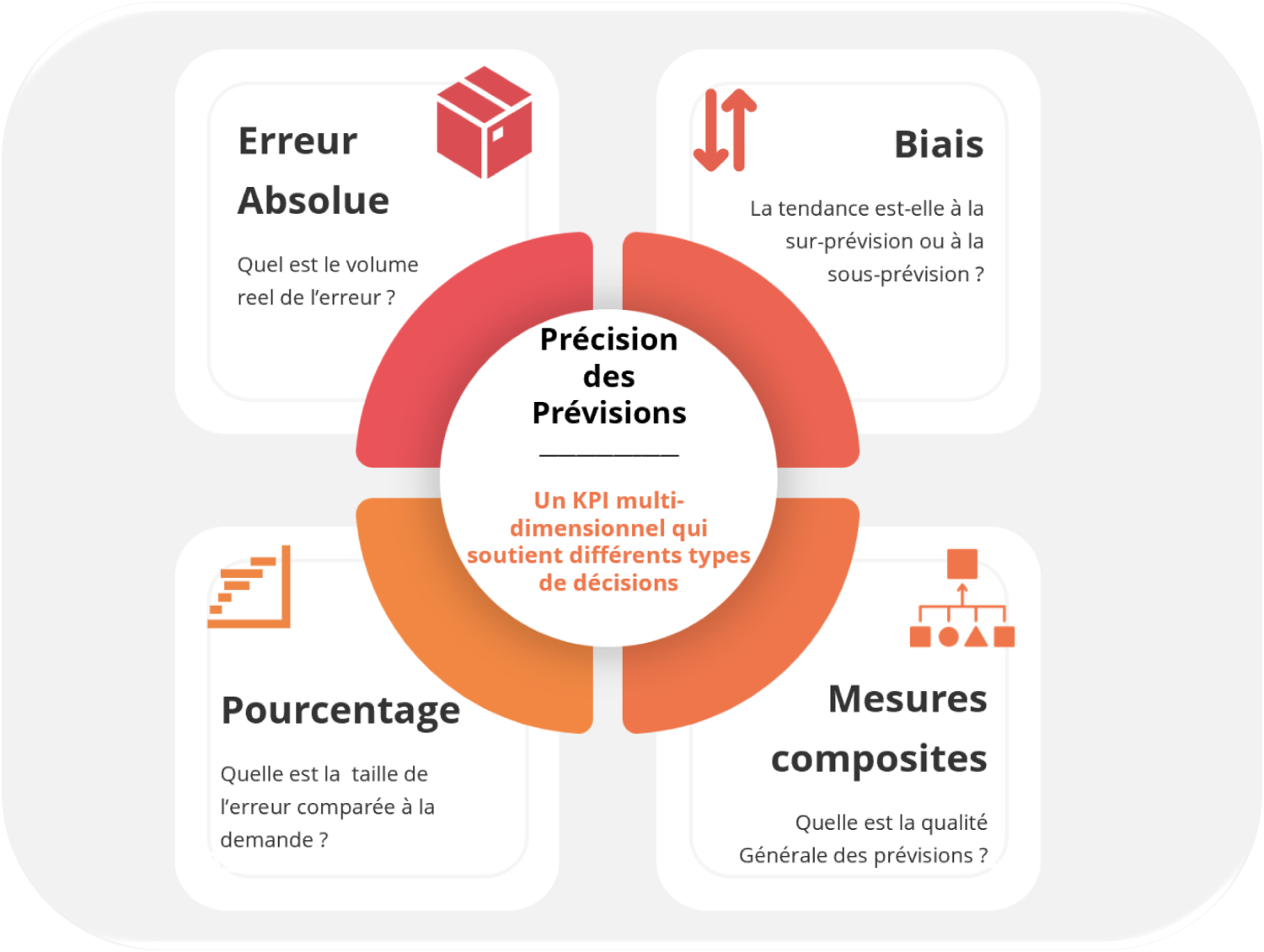
Dans cet article, nous adoptons volontairement une approche plus large, en considérant la précision des prévisions comme un ensemble de mesures complémentaires, nécessaires pour analyser et résoudre des problématiques opérationnelles.
Ces mesures n’ont ni le même objectif, ni la même portée, ni la même pertinence selon les décisions qu’elles doivent éclairer.
Les prévisions de demande soutiennent des décisions de nature très différente. Elles servent d’abord et avant tout à planifier la demande et la production.
Ainsi, selon les besoins, elles peuvent permettre de dimensionner les capacités de production, arbitrer des budgets, piloter des stocks, sécuriser un plan industriel ou encore aligner les équipes commerciales et opérationnelles.
Ces décisions ne s’appuient pas sur les mêmes horizons temporels, n’exposent pas l’entreprise aux mêmes risques et ne tolèrent pas les mêmes types d’erreurs. Dans ce contexte, aucune métrique unique ne peut répondre de manière satisfaisante à l’ensemble de ces enjeux. Une lecture agrégée peut indiquer que les prévisions sont globalement cohérentes avec la trajectoire métier, tandis qu’une lecture plus fine mettra en évidence des écarts significatifs sur certains produits, périodes ou zones géographiques. Ces lectures ne sont pas contradictoires : elles traduisent des besoins d’analyse différents.
Chercher à piloter toutes les décisions à partir d’une seule mesure de précision conduit souvent à des arbitrages approximatifs et à une compréhension partielle de la réalité opérationnelle.
Les mesures de précision des prévisions peuvent être regroupées en quelques grandes familles, toutes au service de différents besoins métier.
Le tableau ci-dessous propose une vue d’ensemble des principales mesures de précision des prévisions, en les reliant aux décisions métier qu’elles permettent d’éclairer. La suite de l’article revient plus en détail sur chacune de ces familles de mesures, afin d’en préciser les apports et les limites.
Type de décision | Ce que l’on cherche à comprendre | Type de mesure pertinente | Rôles principalement concernés |
Planification de capacité | Ampleur réelle de l’écart en volume | Erreur absolue (MAE) | Planificateur de la demande, planificateur de production, équipes de production |
Pilotage des stocks | Risque de surstock ou de rupture | MAE (%); Biais (%) | Chaîne logistique, finance |
Revue de portefeuille | Comparabilité entre produits, marchés ou canaux | MAE (%) | Équipe de planification de la demande, direction, opérations commerciales |
Gouvernance de la prévision | Posture systématique de prévision (sur- ou sous-prévision) | Biais (%) | Responsable de la planification de la demande, direction |
Arbitrage S&OP | Impact global et nature du risque métier | Lecture combinée / mesures composites | Équipe S&OP, direction des opérations, finance |
Ce qui suit adopte une approche avant tout conceptuelle et métier : l’objectif est de clarifier ce que chaque type de mesure cherche à qualifier, plutôt que de s’attarder sur les calculs.
Dans la pratique, ces mesures reposent sur la capacité à comparer la demande observée à des prévisions formulées à différents moments dans le passé. Pawa permet justement de remonter dans le temps, de visualiser les prévisions telles qu’elles existaient à un instant donné, et d’analyser la précision des prévisions en fonction de ces prévisions passées.
Pour le détail des formules mathématiques ainsi que pour les principes de paramétrage de ces indicateurs, notamment en ce qui concerne le choix de l’horizon de mesure, qui peut fortement varier selon les besoins et les équipes, vous pouvez vous référer à l’article dédié à leur mise en œuvre opérationnelle (article 3).
Les mesures d’erreur absolue visent à quantifier l’écart moyen entre la prévision et la demande observée, exprimé dans les mêmes unités que la demande (pièces, palettes, MWh, etc.) .
Elles décrivent donc l’ampleur des erreurs en volume réel et répondent à une question simple : de combien la prévision s’écarte-t-elle, en moyenne, de la réalité ?
Ces mesures permettent par exemple à une équipe logistique de traduire un écart de prévision en impacts concrets : capacité d’entreposage, charge de préparation, risque de rupture ou surstock.
Prenons une situation très concrète. Une usine doit préparer la production d’un lot mensuel d’un produit alimentaire conditionné en sachets. La prévision estime la demande à 1 000 boîtes, tandis que la demande réellement observée atteint finalement 1 150 boîtes. L’écart absolu pour la période est donc de 150 boîtes. Rapporté sur plusieurs mois, un MAE de 150 signifie que, en moyenne, la planification se trompe de 150 boîtes par cycle de production. Pour les équipes opérationnelles, cette valeur n’est pas théorique : elle correspond à un demi-palettier supplémentaire à stocker, à une heure de production non prévue, ou encore à une tournée de livraison additionnelle. Le MAE permet ainsi de raisonner directement en volumes manipulables, et donc en coûts, capacité et charge opérationnelle réelles.
En revanche, comme ces mesures ne rapportent pas l’erreur au niveau d’activité, leur interprétation devient plus difficile dès que l’on compare des produits, marchés ou canaux de tailles très différentes : un même écart absolu peut représenter une erreur majeure dans un petit périmètre et un écart négligeable dans un grand. Si un produit A vend 1 000 unités par mois et un produit B 10 000 unités par mois, un MAE identique de 150 unités n’a pas du tout la même signification : il représente environ 15 % du volume pour A, mais seulement 1,5 % pour B.
Autrement dit, les mesures absolues décrivent bien la taille réelle de l’erreur, mais pas son importance relative, d’où l’intérêt de les compléter par des indicateurs exprimés en pourcentage lorsqu’il s’agit de comparer des périmètres hétérogènes.
En résumé | |
Ce que la mesure dit | L’ampleur réelle de l’erreur en volume (unités, palettes, MWh, etc.) |
Ce qu’elle ne dit pas | L’importance relative de l’erreur par rapport au niveau d’activité |
À qui elle parle | Planificateurs de la demande, production, logistique |
Risque si utilisée seule | Mauvaise comparabilité entre produits ou périmètres de tailles différentes |
Les mesures de biais cherchent à identifier dans quelle direction les prévisions s’écartent de la réalité. Elles mettent en évidence l’existence d’une tendance systématique à sur-prévoir ou à sous-prévoir, en observant si, en moyenne, les erreurs sont plutôt positives ou négatives.
Elles répondent ainsi à une question différente de celle des mesures d’erreur absolue : non pas “de combien la prévision s’écarte-t-elle de la réalité ?”, mais “dans quel sens l’erreur se répète-t-elle au fil du temps ?” Autrement dit, elles éclairent davantage la posture de prévision que son niveau de précision.
Ces mesures présentent un intérêt particulier dans les environnements où les prévisions sont largement influencées par des ajustements humains ou par des règles implicites de gestion. Un biais persistant peut, par exemple, révéler une tendance organisationnelle à sur-protéger les stocks, à surestimer la demande pour sécuriser la capacité, ou au contraire à systématiquement sous-prévoir dans des contextes de contraintes de production ou d’objectifs commerciaux conservateurs.
Supposons faire partie d’une entreprise de cosmétique au sein de laquelle les équipes commerciales ajustent régulièrement les prévisions à la hausse avant la production, par crainte de ruptures lors des pics promotionnels. Sur six mois consécutifs, la demande réelle se situe systématiquement en dessous des prévisions : +90 unités, +120 unités, +85 unités, +110 unités, +95 unités, +130 unités. En moyenne, l’erreur conserve un signe positif : la mesure de biais met clairement en évidence une tendance structurelle à la sur-prévision.
Côté finance, le biais éclaire des indicateurs plus globaux comme l’immobilisation de cash, l’augmentation des coûts de stockage… mais aussi la hausse du taux de produits périmés ou dépréciés en fin de cycle, particulièrement critique dans des gammes à durée de vie limitée. Autrement dit, la mesure de biais devient ici un outil de diagnostic comportemental et économique, révélant qu’une logique de “sur-protection” guide la prévision bien plus qu’une représentation fidèle de la demande.
En revanche, les mesures de biais comportent une limite majeure : comme elles conservent le signe des erreurs, des écarts positifs et négatifs peuvent se compenser. Une série de fortes sur-prévisions suivies de fortes sous-prévisions peut ainsi conduire à un biais moyen proche de zéro, alors même que la prévision est très instable et peu fiable. L’absence de biais n’implique donc pas une bonne précision, mais uniquement un équilibre moyen entre excès et déficit de prévision.
Cette limite apparaît clairement lorsqu’on l’illustre par un cas concret.
Supposons qu’un produit affiche les écarts suivants sur quatre mois entre prévision et demande réelle : +120 unités, +140 unités, −130 unités et −150 unités. La moyenne de ces erreurs est proche de zéro, ce qui suggère un biais nul. Pourtant, chaque mois présente des écarts importants, et la prévision reste fortement erratique. Dans ce cas, la mesure de biais masque la volatilité des erreurs et doit impérativement être complétée par une mesure d’erreur absolue.
Ainsi, les mesures de biais sont essentielles pour comprendre l’orientation structurelle des prévisions, mais elles ne renseignent pas sur l’ampleur réelle des écarts. Elles doivent donc être lues en complément des mesures d’erreur, et non comme un indicateur autonome de la qualité des prévisions.
| En résumé |
Ce que la mesure dit | Le sens dans lequel la prévision s’écarte systématiquement de la réalité (sur- ou sous-prévision) |
Ce qu’elle ne dit pas | L’ampleur réelle des écarts en volume |
À qui elle parle | Responsables de la planification, direction, finance |
Risque si utilisée seule | Masquage d’erreurs importantes par compensation des écarts positifs et négatifs |
Contrairement aux mesures d’erreur absolue, les mesures en pourcentage cherchent à fournir une lecture relative de l’erreur, indépendamment du niveau de volume. Ces indicateurs répondent ainsi à une question différente : quelle est la part de l’erreur par rapport à la demande ?
Cette approche présente un avantage important lorsqu’il s’agit de comparer des périmètres hétérogènes : produits, marchés, pays ou canaux dont les niveaux d’activité sont très différents. Une erreur de 150 unités n’a pas la même signification selon que l’on vend 1 000 ou 10 000 unités ; exprimée en pourcentage, elle devient en revanche comparable entre contextes. C’est ce qui fait du MAE% un indicateur particulièrement utile pour le suivi transversal, le pilotage d’un portefeuille ou la communication auprès d’équipes non techniques.
Cet intérêt apparaît clairement dans une situation opérationnelle courante. Une direction cherche à comparer la performance de prévision de deux familles produits : les produits stratégiques haut volume et les produits longue traîne. En exprimant l’erreur en pourcentage, le responsable peut identifier que certaines références de la longue traîne présentent 25 % d’écart moyen, contre 6 % pour les produits cœur de gamme, information impossible à lire avec des erreurs exprilogistiquemées uniquement en unités. Ici, la mesure en pourcentage joue pleinement son rôle : elle permet d’objectiver les priorités d’amélioration à l’échelle du portefeuille.
Cependant, cette normalisation a aussi ses limites. Dans les contextes de faibles volumes, une petite variation en unités peut conduire à des pourcentages très élevés, qui donnent une image exagérée de l’erreur. À l’inverse, un pourcentage apparemment satisfaisant peut masquer des écarts importants en volume absolu et donc un impact opérationnel significatif. Autrement dit, ces mesures facilitent la comparaison, mais elles peuvent diluer la matérialité des écarts si elles sont utilisées seules.
Cette ambiguïté apparaît clairement lorsqu’on l’illustre par un cas concret. Supposons qu’un produit vende en moyenne 10 000 unités par mois. Une erreur de 200 unités correspond à 2 % d’écart, ce qui peut sembler acceptable d’un point de vue global. Pourtant, ces 200 unités peuvent représenter plusieurs palettes supplémentaires à stocker, une augmentation des coûts logistiques, ou au contraire une rupture sur un point de vente clé : leur impact reste bien réel, même si le pourcentage paraît faible.
À l’inverse, un autre produit vend en moyenne 50 unités par mois. Une erreur de 10 unités correspond ici à 20 % d’écart, ce qui donne l’impression d’une prévision très mauvaise alors que, dans les faits, l’impact opérationnel reste limité. Le pourcentage reflète correctement la proportion de l’erreur, mais pas nécessairement sa gravité économique.
En somme, les mesures en pourcentage constituent d’excellents indicateurs de comparabilité et de pilotage global, mais elles ne remplacent pas les mesures exprimées en volume réel. Leur lecture devient plus pertinente lorsqu’elles sont mises en regard des erreurs absolues et du contexte métier, afin de concilier comparabilité statistique et pertinence opérationnelle.
| En résumé |
Ce que la mesure dit | La taille de l’erreur relative par rapport à la demande |
Ce qu’elle ne dit pas | L’impact opérationnel réel en volume |
À qui elle parle | Management, planification, pilotage de portefeuille |
Risque si utilisée seule | Sur-interprétation des erreurs sur faibles volumes ou sous-estimation des impacts sur forts volumes |
Les scores et mesures composites cherchent à aller au-delà d’une lecture unidimensionnelle de la performance des prévisions, en combinant plusieurs dimensions de l’erreur au sein d’un même indicateur. Là où une mesure isolée décrit soit l’ampleur des écarts, soit leur orientation, un score composite vise à proposer une lecture plus holistique et pragmatique de la qualité des prévisions, en intégrant par exemple à la fois la taille de l’erreur et la présence éventuelle d’un biais structurel.
Dans cette logique, certaines organisations optent pour des approches simples mais robustes, consistant à suivre simultanément deux indicateurs complémentaires plutôt qu’un score unique. C’est notamment le cas dans Pawa, où la performance des prévisions est évaluée à travers une combinaison de MAE (erreur absolue moyenne) et de mesures de biais. Le MAE permet d’apprécier l’ampleur concrète des écarts en volume, tandis que le biais renseigne sur l’orientation systématique de la prévision (plutôt au-dessus ou au-dessous de la demande). Ensemble, ces deux lectures offrent un diagnostic plus riche que chacune prise isolément.
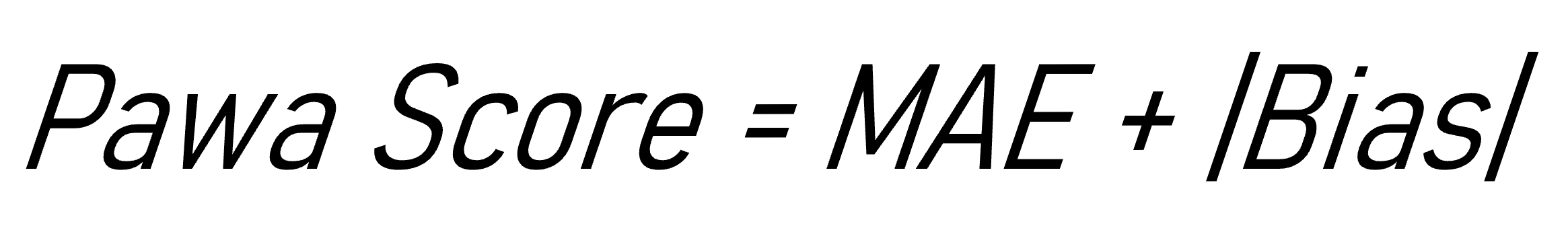
On peut l’illustrer par une situation concrète. Deux familles de produits présentent un MAE identique de 180 unités. Si l’on ne regarde que cette mesure, elles semblent poser le même niveau de risque pour les opérations. Mais l’analyse du biais révèle deux réalités très différentes : dans la première famille, les erreurs sont presque toujours positives, signe d’une sur-prévision structurelle qui conduit à des stocks élevés, à des dépréciations et, côté finance, à une hausse du taux de produits périmés. Dans la seconde famille, le biais est proche de zéro mais les erreurs alternent entre sur et sous-prévision, générant surtout de la volatilité opérationnelle (variabilité de charge, réajustements fréquents, tensions ponctuelles en capacité).
Dans ce cas, la combinaison MAE + biais permet de distinguer deux types de problèmes qui n’appellent pas les mêmes actions : d’un côté, un enjeu de posture et de gouvernance de la prévision ; de l’autre, un enjeu de stabilité du processus et de qualité du signal. C’est précisément ce type de lecture enrichie que rendent possibles les mesures composites.
D’autres approches vont plus loin en intégrant des pondérations métier ou des dimensions économiques : priorisation par valeur, criticité produit, coût de la rupture ou du surstock, ou encore indicateurs de type la valeur ajoutée réelle de la prévision (FVA —> Forecast Value Added) visant à mesurer la contribution réelle des ajustements humains par rapport à une baseline statistique. Ces scores peuvent être particulièrement utiles dans des environnements complexes, où la question n’est pas seulement de mesurer l’erreur, mais de comprendre où elle compte vraiment et comment elle se traduit en impact opérationnel.
Ils présentent toutefois une limite importante : plus un score intègre de dimensions, plus il risque de devenir opaque. Lorsque la logique de construction n’est pas explicitement documentée (choix des pondérations, rôle de chaque composante, conventions de calcul) le score peut être difficile à interpréter, voire conduire à des décisions biaisées.
Pour résumer, les mesures composites peuvent offrir une lecture plus riche et plus proche des enjeux réels, à condition que leur conception reste transparente, explicable et alignée avec les objectifs métiers.
| Résumé |
Ce que la mesure dit | Une lecture enrichie combinant plusieurs dimensions de l’erreur |
Ce qu’elle ne dit pas | La contribution exacte de chaque composante si le score est peu explicité |
À qui elle parle | S&OP, direction des opérations, finance |
Risque si utilisée seule | Opacité du diagnostic si la construction du score n’est pas transparente |

Aucune mesure ne peut, à elle seule, rendre compte de la complexité des enjeux de la chaîne logistique. Chaque indicateur apporte une lecture partielle, orientée, parfois biaisée, de la réalité. C’est précisément pour cette raison que leur combinaison, leur mise en perspective et leur interprétation métier sont déterminantes.
Les organisations ont donc pour défi de construire une lecture de la performance de prévision adaptée aux décisions à soutenir, aux risques à maîtriser et aux comportements à comprendre. Utilisées de manière complémentaire et contextualisée, les mesures de précision deviennent alors des outils précieux d’aide à la décision.
Comment configurer une mesure de forecast accuracy dans Pawa
Cet article vous explique comment configurer la précision des prévisions de ventes dans Pawa
Quelles sont les mesures de précision des prévisions dans Pawa ?
Cet article présente les principales mesures de précision des prévisions disponibles dans Pawa et donne un aperçu de ce que chacune permet de lire.
